AI旋风了解到,谷歌近日在GitHub页面发布了一则令人瞩目的博文,介绍了其最新推出的VLOGGER AI模型。这一创新技术让用户仅通过输入一张肖像照片和一段音频内容,就能让照片中的人物“活”起来,生动而富有表情地朗读音频内容。这一技术的推出,标志着人工智能在图像与语音交互领域迈出了重要的一步。
VLOGGER AI是一种专为虚拟肖像设计的多模态Diffusion模型,其训练基于MENTOR数据库,这个数据库中包含了超过80万名人物肖像以及累计超过2200小时的影片素材。正是这一庞大的数据基础,使得VLOGGER能够生成具有不同种族、年龄、穿着和姿势的肖像影片,极大地丰富了其应用场景和可能性。
据研究人员介绍,相较于此前的多模态技术,VLOGGER AI的优势在于其无需对每个人进行单独训练,也不依赖于人脸检测和裁剪技术。它能够生成完整的图像,而不仅仅是人脸或嘴唇的局部,并且在生成过程中充分考虑了广泛场景的变化,如可见躯干或不同主体身份等因素。这些特点使得VLOGGER在合成交流场景中的人类形象时更加自然和逼真。
谷歌将VLOGGER视为迈向“通用聊天机器人”的重要一步。想象一下,未来我们的AI助手不仅能够通过语音与我们交流,还能通过手势、眼神等更加自然的方式与我们互动。这将极大地提升人机交互的体验,使得AI更加融入我们的日常生活。
此外,VLOGGER AI的应用场景也十分广泛。在教育领域,它可以用于制作更加生动有趣的课件和教程;在新闻报道中,它可以帮助记者快速生成具有真实感的虚拟播报员;在影视制作中,VLOGGER则可以用于剪辑和调整既有影片中的表情,让角色更加符合剧情需要。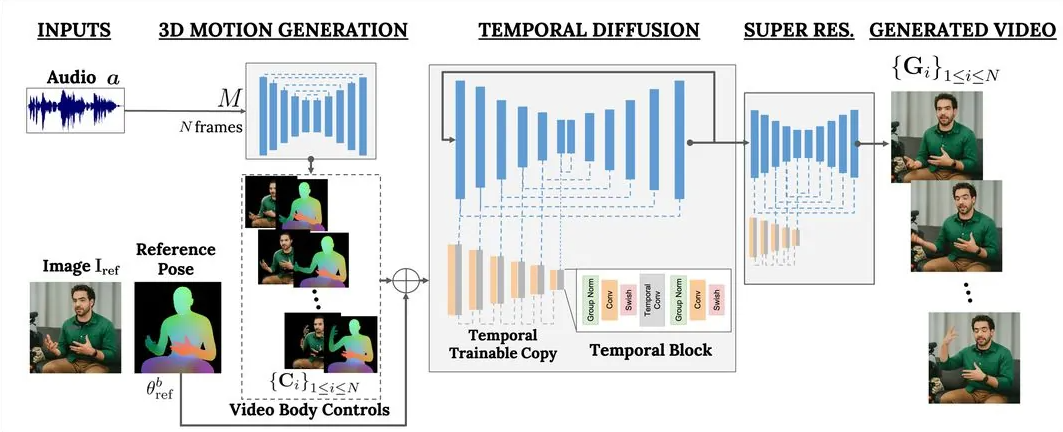
AI旋风认为,VLOGGER AI的推出不仅展示了谷歌在人工智能领域的深厚实力,也为我们揭示了未来人机交互的新方向。随着技术的不断进步和完善,我们有理由相信,未来的AI将更加智能、更加自然,成为我们生活中不可或缺的一部分。
然而,在享受技术带来的便利的同时,我们也应该意识到其中可能存在的风险和挑战。例如,如何确保生成的视频内容真实可信、如何保护用户隐私等问题都需要我们认真思考和解决。
总的来说,谷歌的VLOGGER AI技术是一项具有划时代意义的创新,它将为我们带来更加丰富多彩的视觉体验,并推动人工智能技术在各个领域的应用和发展。我们期待看到更多类似的技术成果在未来不断涌现,为我们的生活带来更多惊喜和便利。
 渝公网安备50019002504809号
渝公网安备50019002504809号