在虚拟形象生成领域,一项革命性的技术正在悄然崛起。长久以来,尽管对话形象生成模型在口型同步方面取得了显著进展,但在控制和传达形象的细节表情和情感方面始终存在局限,导致生成的视频缺乏生动性和可控性。然而,近日北京大学的研究团队打破了这一僵局,他们提出的InstructAvatar技术,通过自然语言输入实现了对虚拟形象情感和面部动作的精准控制,为虚拟形象生成领域带来了全新的可能。
InstructAvatar的突破之处在于其通过自然语言界面来控制虚拟形象的情感和面部动作。用户只需输入简单的文本指令,就能让虚拟形象展现出丰富的情感和动作变化。这一技术不仅解决了传统方法中生成视频缺乏生动性的问题,更在细粒度情绪控制、口型同步质量和自然度方面展现出了卓越的性能。
为了实现这一突破,InstructAvatar采用了先进的框架设计。该框架由两个核心组件构成:变分自动编码器(VAE)和基于扩散模型的动作生成器。VAE负责将动作信息从视频中解耦,而动作生成器则根据音频和指令生成器生成的动作潜变量来生成最终的视频。在推理过程中,模型通过迭代去噪高斯噪声来获取预测的动作潜变量,并结合用户提供的肖像,使用VAE的解码器生成最终的视频。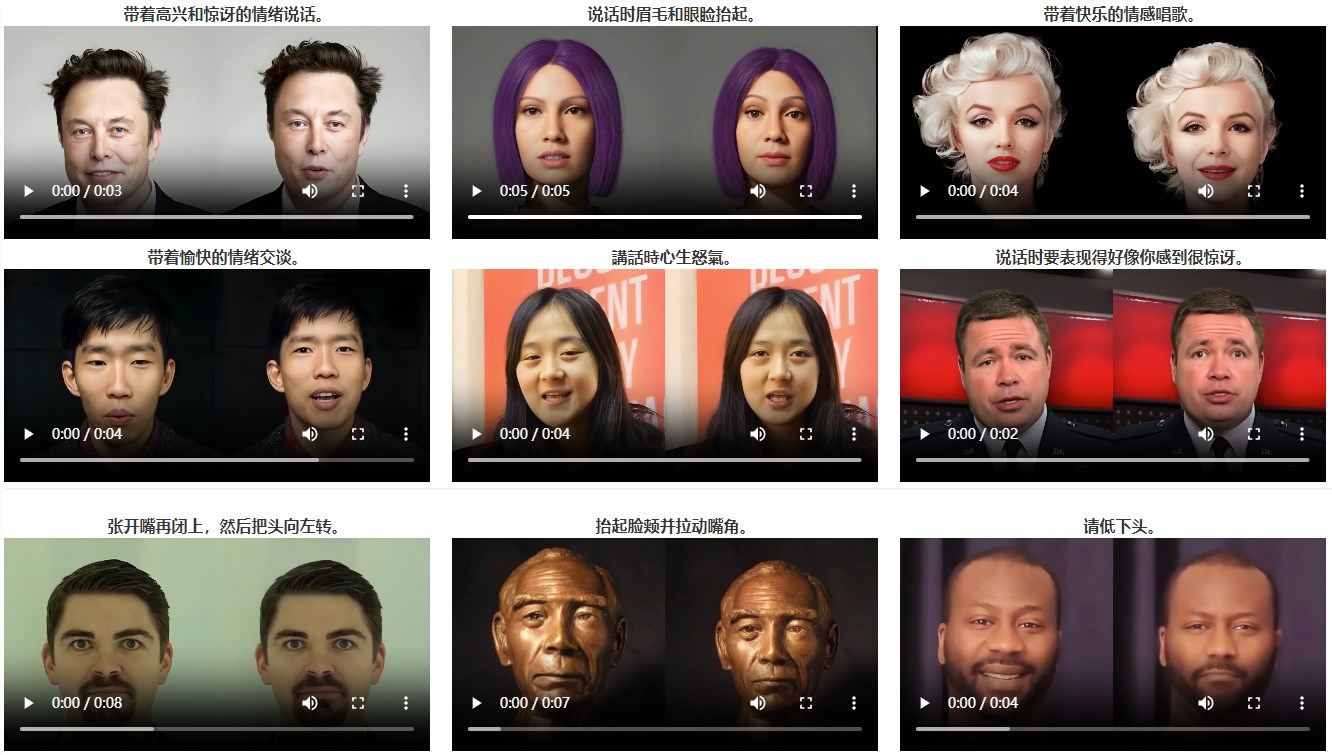
通过与基线模型的定性比较,InstructAvatar在唇同步质量和情感可控性方面取得了显著的优势。生成的虚拟形象不仅能够准确同步口型,还能展现出自然且生动的表情。更重要的是,InstructAvatar在保留身份特征的同时,也实现了对虚拟形象情感和动作的细粒度控制。
值得一提的是,InstructAvatar仅基于文本输入推断说话的情感,这在直观上提出了一个更具挑战性的任务。然而,该模型不仅成功应对了这一挑战,还展现出了精确的情感控制能力。此外,InstructAvatar支持更广泛的指令范围,超出了大多数基线模型的能力。
AI旋风认为,InstructAvatar的推出将极大地推动虚拟形象生成领域的发展。该技术不仅为用户提供了更加生动、可控的虚拟形象生成体验,还为游戏、教育、娱乐等多个领域带来了广阔的应用前景。随着技术的不断成熟和普及,我们有理由相信,InstructAvatar将成为未来虚拟形象生成领域的重要技术支撑。
在未来,我们期待看到更多基于InstructAvatar技术的创新应用。无论是在游戏中的角色表情和动作生成,还是在教育领域的虚拟人物互动教学,亦或是在娱乐领域的虚拟偶像表演,InstructAvatar都将展现出其独特的魅力和价值。让我们共同期待这一技术为我们的生活带来更多精彩和可能性。
 渝公网安备50019002504809号
渝公网安备50019002504809号