在人工智能领域,一项令人瞩目的突破正在悄然发生。据了解,伊利诺伊大学厄巴纳-香槟分校(UIUC)与BigCode组织的研究者共同推出了StarCoder2-15B-Instruct代码大模型,该模型在无需依赖OpenAI等商业大模型数据的情况下,成功登顶代码生成性能榜单,展现了强大的自主研发能力。
StarCoder2-15B-Instruct的发布标志着AI在代码生成领域的新里程碑。这款模型凭借纯自对齐策略,通过自我生成数千个指令-响应对,直接对StarCoder-15B基座模型进行微调,实现了在代码生成任务上的显著突破。相较于依赖昂贵人工标注数据或商业大模型数据的传统方法,StarCoder2-15B-Instruct展现了更高的自主可控性和灵活性。
在HumanEval测试中,StarCoder2-15B-Instruct取得了令人瞩目的成绩,以72.6%的Pass@1成绩超越了CodeLlama-70B-Instruct的72.0%,证明了其强大的代码生成能力。而在LiveCodeBench数据集的评估中,该模型更是表现出色,甚至超越了基于GPT-4生成数据训练的同类模型。这一成果充分展示了通过自身数据训练的大模型同样能够有效地学习如何与人类偏好对齐,为AI在代码生成领域的应用提供了新思路。
StarCoder2-15B-Instruct的成功得益于其独特的数据生成流程。该流程主要包括三个核心步骤:种子代码片段的采集、多样化指令的生成和高质量响应的生成。首先,研究者们从开源代码片段中选取高质量、多样化的种子函数作为起点;然后,基于这些种子函数的不同编程概念,StarCoder2-15B-Instruct能够创建出多样化且真实的代码指令;最后,通过自我验证的方式确保生成的响应是准确且高质量的。这种自我驱动的数据生成方式不仅降低了对外部数据的依赖,还提高了模型的自我调优能力。
在备受瞩目的EvalPlus基准测试中,StarCoder2-15B-Instruct展现出了强大的性能。该模型不仅超越了规模更大的Grok-1Command-R+和DBRX等模型,还与Snowflake Arctic480B和Mixtral-8x22B-Instruct等业界翘楚性能相当。此外,在LiveCodeBench和DS-1000等评估平台上,StarCoder2-15B-Instruct也展现出了强大的实力,进一步证明了其卓越的性能和广泛的应用前景。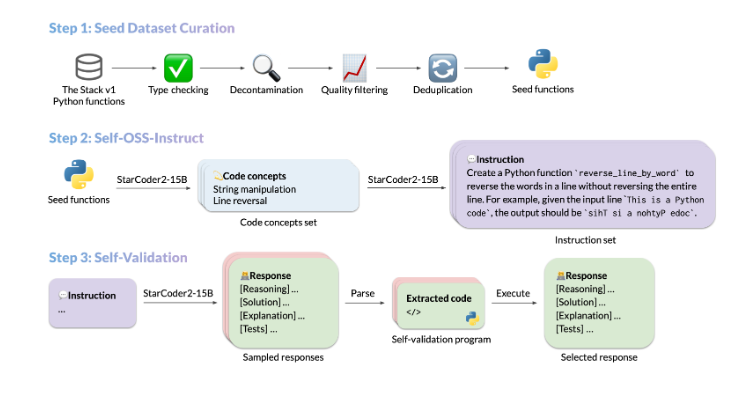
AI旋风认为,StarCoder2-15B-Instruct的成功发布是AI领域的一大突破。这款模型不仅展示了通过自我调优构建高性能代码模型的可能性,还为未来该领域的研究和发展奠定了坚实的基础。同时,StarCoder2-15B-Instruct的开源数据集和训练流程也为广大研究者提供了宝贵的资源和参考。
该项目的成功实施得到了美国东北大学Arjun Guha课题组、加州大学伯克利分校、ServiceNow和Hugging Face等机构的鼎力支持。这些机构的贡献不仅为项目的推进提供了强大的技术支撑和资源保障,还推动了AI在代码生成领域的交流与合作。
展望未来,随着AI技术的不断发展和完善,我们有理由相信StarCoder2-15B-Instruct这样的高性能代码模型将在更多领域发挥重要作用。无论是软件开发、自动编程还是其他相关领域,这些先进的AI技术都将为我们带来更加便捷、高效和智能的解决方案。
 渝公网安备50019002504809号
渝公网安备50019002504809号