在人工智能的浪潮中,视频理解和字幕生成技术正逐步成为行业关注的焦点。近日,一组研究人员成功推出了ShareGPT4Video系列,这一创新模型旨在通过精准的字幕促进大规模视频语言模型(LVLMs)的视频理解以及文本到视频模型(T2VMs)的视频生成,标志着视频处理领域又迈出了重要一步。
ShareGPT4Video系列包括三大核心组件:ShareGPT4Video、ShareCaptioner-Video和ShareGPT4Video-8B。这些组件共同构成了一个强大的视频处理框架,旨在解决视频理解和字幕生成中的关键挑战。
ShareGPT4Video是一个由GPT4V注释的密集字幕数据集,包含了40,000个不同长度和来源的视频。通过精心设计的数据过滤和注释策略,这些视频的字幕不仅数量庞大,而且质量上乘,涵盖了广泛的类别和丰富的世界知识。
ShareCaptioner-Video则是一个高效且功能强大的视频字幕生成模型。它能够快速为任意视频生成高质量的字幕,无论是分辨率、宽高比还是视频长度,都能保持稳定、可扩展且高效的性能。目前,该模型已经成功注释了4,800,000个高质量美学视频,并在文本到视频生成任务上验证了其有效性。
ShareGPT4Video-8B是一个卓越的LVLM,它在三个先进的视频基准测试中取得了SOTA性能。这一模型的成功验证,进一步证明了ShareGPT4Video系列在视频理解方面的强大能力。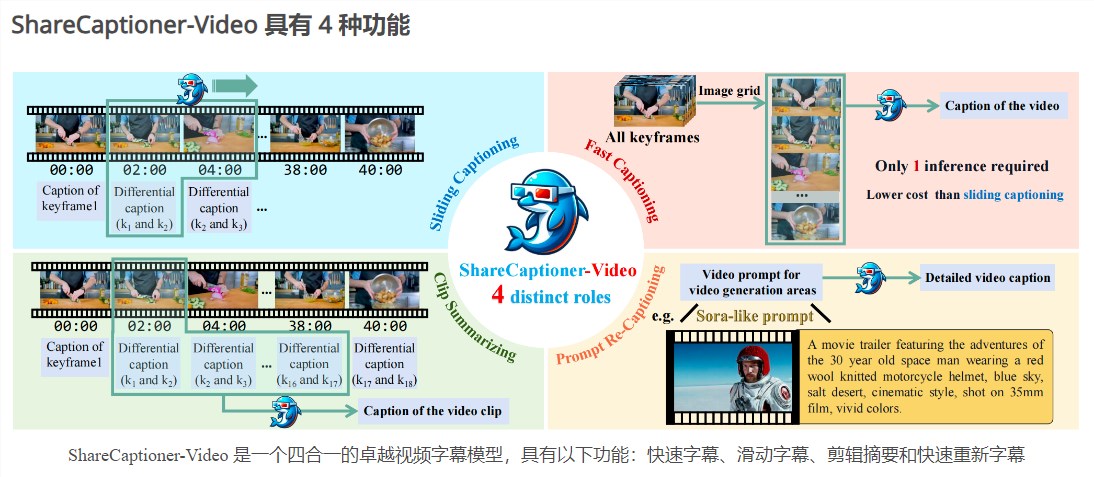
在视频字幕生成过程中,研究人员面临着三大挑战:理解帧间精确的时间变化、描述帧内详细的内容以及对于任意长度视频的帧数量可扩展性。为了克服这些挑战,研究团队精心设计了差分视频字幕策略。
这一策略通过深入分析视频帧间的变化,结合丰富的世界知识和物体属性,为视频生成了详细且精确的字幕。同时,该策略还具有良好的可扩展性,能够处理任意长度的视频,并保持稳定的性能。
ShareGPT4Video系列不仅具有强大的视频理解和字幕生成能力,还具备多项独特的功能和优势。
首先,ShareGPT4Video数据集包含了丰富的视频类别和字幕信息,为视频处理领域的研究提供了宝贵的资源。其次,ShareCaptioner-Video模型能够快速为任意视频生成高质量的字幕,极大地提高了视频处理的效率。最后,ShareGPT4Video-8B模型在视频理解方面取得了出色的性能,为视频内容分析和挖掘提供了有力的支持。
ShareGPT4Video系列的发布,无疑为视频处理和人工智能领域带来了新的机遇和挑战。通过精准的字幕生成和高质量的视频理解,这一模型将推动视频内容处理技术的发展,为用户带来更加智能、便捷的视频体验。同时,随着AI技术的不断进步和应用场景的不断拓展,ShareGPT4Video系列还将为更多领域的研究和应用提供有力支持。我们期待看到这一模型在未来的发展中能够取得更加卓越的成果。
 渝公网安备50019002504809号
渝公网安备50019002504809号