在人工智能的浩瀚星空中,每一次技术的革新都如同璀璨星辰,照亮着未来的道路。腾讯人工智能实验室最新研究成果揭开了神秘面纱——VTA-LDM(隐含对齐视频到音频生成)模型。这一创新技术的问世,不仅标志着视频到音频生成领域的一次重大飞跃,更为我们描绘了一幅视听融合、无限想象的未来图景。
随着文本到视频生成技术的日益成熟,如何跨越视觉与听觉的界限,实现视频与音频之间的精准对齐与和谐共生,成为了当前AI研究的一大热点与挑战。腾讯AI实验室的VTA-LDM模型正是在这一背景下应运而生,它以独特的隐含对齐技术为核心,为视频到音频的生成问题提供了前所未有的解决方案。
VTA-LDM模型的核心魅力在于其隐含对齐机制。通过这一机制,模型能够深入理解视频内容的语义信息,并据此生成与之紧密匹配的音频内容。这种从视觉到听觉的跨模态转换,不仅要求生成的音频在音质上达到专业水准,更需在情感表达、场景氛围等方面与视频内容高度一致。据了解,为了实现这一目标,腾讯AI实验室的研究团队在模型设计上倾注了大量心血,通过结合先进的视觉编码器、辅助嵌入技术和数据增强策略,确保了生成音频的准确性与一致性。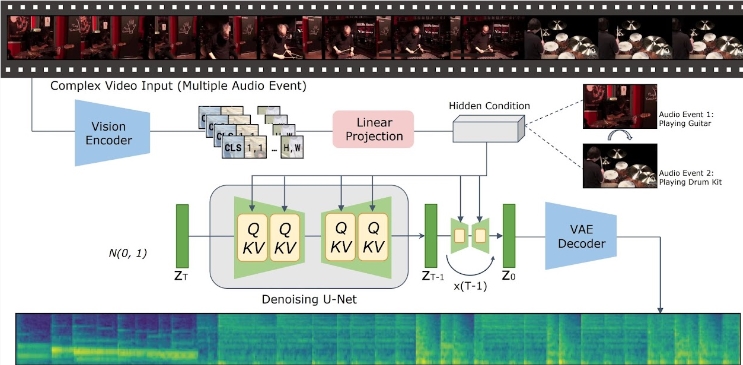
为了验证VTA-LDM模型的有效性,研究团队进行了一系列严谨的消融实验。这些实验不仅涵盖了不同视觉编码器和辅助嵌入对生成效果的影响,还深入探讨了模型在生成质量和视频音频同步对齐方面的表现。实验结果显示,VTA-LDM模型在各项指标上均表现出色,达到了当前技术的最前沿水平。这一成就,不仅是对腾讯AI实验室技术实力的有力证明,更是对视频到音频生成领域的一次重大贡献。
在模型的应用方面,VTA-LDM同样展现出了极高的便捷性。用户只需将视频片段放入指定的数据目录,并运行提供的推理脚本,即可在短时间内生成与之对应的音频内容。此外,研究团队还贴心地提供了一套工具集,帮助用户轻松实现音频与视频的合并操作,进一步提升了应用的实用性和用户体验。
为了满足不同研究者和开发者的需求,VTA-LDM模型提供了多个版本供用户选择。从基础模型到多种增强模型,每个版本都针对不同的应用场景和实验需求进行了优化。这种灵活多样的选择方案,不仅为用户提供了更多的可能性,也促进了VTA-LDM模型在不同领域和场景下的广泛应用。
VTA-LDM模型的推出,无疑为视频到音频生成领域注入了一股强劲的动力。它不仅解决了传统方法中存在的诸多难题,更为我们展示了一个视听融合、无限可能的未来世界。AI旋风相信,随着VTA-LDM模型的不断完善和推广应用,它将在影视制作、游戏开发、虚拟现实等多个领域发挥重要作用,推动相关技术的快速发展和创新应用。同时,我们也期待更多像腾讯AI实验室这样的顶尖团队能够持续探索未知领域,为我们带来更多令人惊叹的科技成果。
 渝公网安备50019002504809号
渝公网安备50019002504809号