在科技日新月异的今天,人工智能领域的每一次进步都足以引发广泛关注。近日,OpenAI在深夜举行了一场别开生面的直播活动,正式推出了GPT-4o的原生图像生成功能。这一消息犹如一颗石子投入平静的湖面,瞬间在科技界掀起了波澜。此次GPT-4o的升级,不仅标志着OpenAI在图像生成技术上的重大突破,更预示着多模态人工智能时代的到来。
就在不久前,谷歌刚刚推出了其地表最强模型Gemini 2.5 Pro,引发了业界的广泛关注。面对谷歌的强势挑战,OpenAI并未退缩,而是选择了迎难而上。在直播中,OpenAI的首席执行官萨姆·奥尔特曼(Sam Altman)亲自带队,展示了GPT-4o在图像生成技术上的全面升级。从自拍变梗图、相对论漫画,到文本渲染、多轮交互生成和指令遵循,GPT-4o的表现令人眼前一亮。
在直播的高潮部分,奥尔特曼亲自上阵,与团队成员一起自拍了一张照片,随后GPT-4o迅速将这张照片转换成了动漫风格的版本。紧接着,他们更是官方玩梗,让模型在图片上添加了一段“Feel The AGI”的文字,一张充满趣味性的表情包就此诞生。这一过程,不仅展示了GPT-4o作为全能模型的强大能力,更体现了OpenAI在图像生成技术上的深厚积累。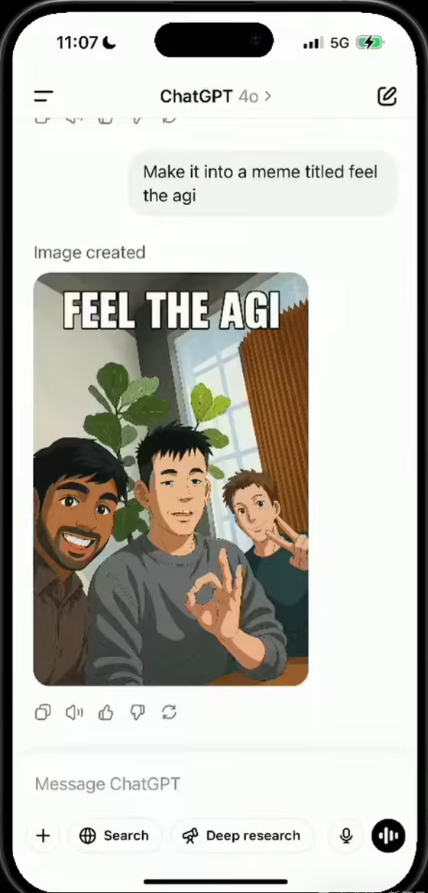
值得注意的是,GPT-4o的图像生成功能并非简单的图像转换或生成,而是基于其全模态能力的全面融合。OpenAI多模态研究的负责人Gabe在直播中介绍道,早在两年前,当项目刚刚启动时,他就对GPT-4如何原生支持图像模型充满了好奇。一年后,当模型完成训练时,他看到了令人兴奋的迹象。从GPT-2以来,他已经很久没有这种感觉了——这是一个疯狂的时刻。
在直播中,GPT-4o展示了其强大的图像生成能力。通过给出特定的prompt,GPT-4o能够迅速生成符合要求的图像,完全还原了要求中的细节和风格。例如,当要求生成一幅描述相对论的漫画时,GPT-4o不仅准确地理解了提示词,还巧妙地加入了幽默元素,使得生成的漫画既通俗易懂又充满趣味性。这一过程,充分展示了GPT-4o在理解和生成图像方面的卓越能力。
此外,GPT-4o在图像生成过程中还充分利用了其世界知识。在生成漫画的过程中,模型很可能利用了自己的世界知识对提示词进行了扩展和丰富,从而生成了更加符合要求的图像。这一特点使得GPT-4o在图像生成方面更加智能和高效。
除了漫画生成外,GPT-4o还展示了其在文本渲染、多轮交互生成和指令遵循等方面的强大能力。在文本渲染方面,GPT-4o能够精确地将文字与图像融合在一起,使得生成的图像更加具有表现力和感染力。在多轮交互生成方面,GPT-4o能够基于聊天上下文中的图像和文本进行构建,确保生成的图像始终保持一致性。在指令遵循方面,GPT-4o不仅能够遵循详细的提示词,还能够处理多达10-20个不同的物体,并且物体与其特征和关系的更紧密绑定使得控制更加精准。
然而,尽管GPT-4o的图像生成功能如此强大,但OpenAI仍然选择推迟了免费版ChatGPT图像功能的上线时间。奥尔特曼今天在 X 上承认,ChatGPT中图像生成工具的受欢迎程度远超预期,因此免费版用户的上线计划将不得不推迟一段时间。这一决定虽然可能会让部分用户感到失望,但也可以看出OpenAI对于技术质量和用户体验的高度重视。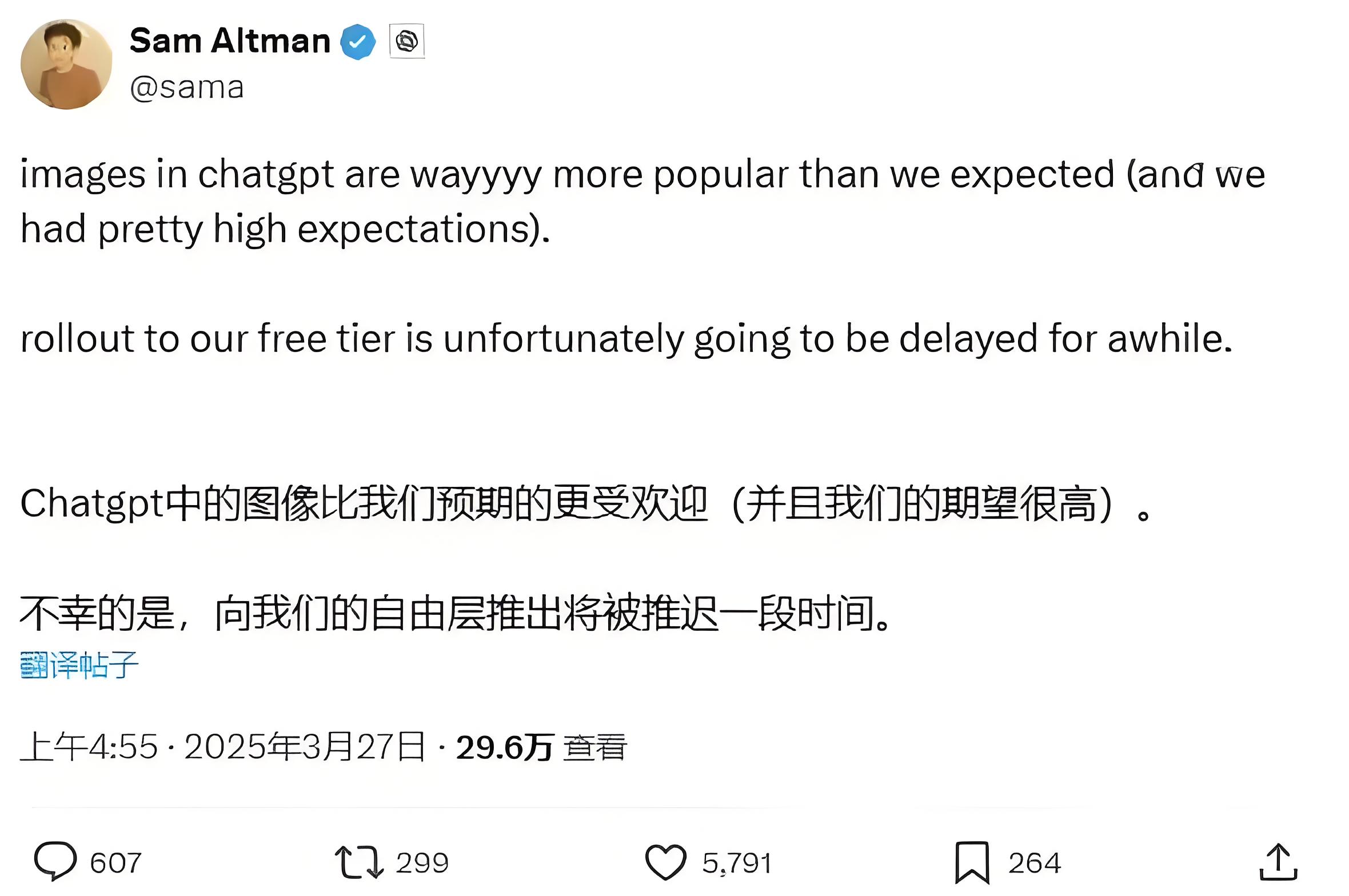
目前,GPT-4o的图像生成功能已经向ChatGPT Plus、Pro、Team和付费用户推出。虽然免费用户还需要等待一段时间才能体验到这一功能,但AI旋风相信,随着AI技术的不断进步和用户的不断增加,GPT-4o的图像生成功能将会在未来发挥更加重要的作用。
总的来说,GPT-4o的原生图像生成功能的发布标志着OpenAI在人工智能领域的又一次重大突破。这一功能不仅提升了ChatGPT的实用性和趣味性,更为多模态人工智能的发展开辟了新的道路。相信随着技术的不断进步和应用场景的不断拓展,GPT-4o的图像生成功能将会在未来发挥更加广泛和深入的作用,为人们的生活和工作带来更多的便利和惊喜。
 渝公网安备50019002504809号
渝公网安备50019002504809号