在人工智能的浪潮中,Refuel AI以其独特的创新能力和对技术前沿的敏锐洞察,再次为业界带来了惊喜。近日,Refuel AI正式宣布推出两款专为数据标注、清洗和丰富任务设计的大型语言模型(LLM)——RefuelLLM-2和RefuelLLM-2-small,旨在通过先进的AI技术提高处理大规模数据集的效率。
AI旋风认为,RefuelLLM-2的推出,标志着数据标注和清洗领域迎来了一次重大的技术革新。该模型不仅能够自动识别和标记数据中的关键信息,还能自动检测并修正数据中的错误或不一致性,甚至能够根据现有数据自动补充缺失信息或提供额外上下文,从而极大地增加了数据的价值和可用性。
RefuelLLM-2的自动化数据标注功能,可以大大减轻人工标注的负担,提高数据处理的效率。它不仅能够准确识别并分类数据,还能解析特定属性,确保数据的准确性和完整性。这一功能对于大规模数据集的处理尤为重要,可以显著减少人工干预,降低错误率,提高数据质量。
除了自动化数据标注外,RefuelLLM-2还具备强大的数据清洗能力。它能够自动检测并修正数据中的错误或不一致性,如拼写错误、格式问题等,确保数据的准确性和一致性。这一功能对于提升数据质量、降低数据处理成本具有重要意义。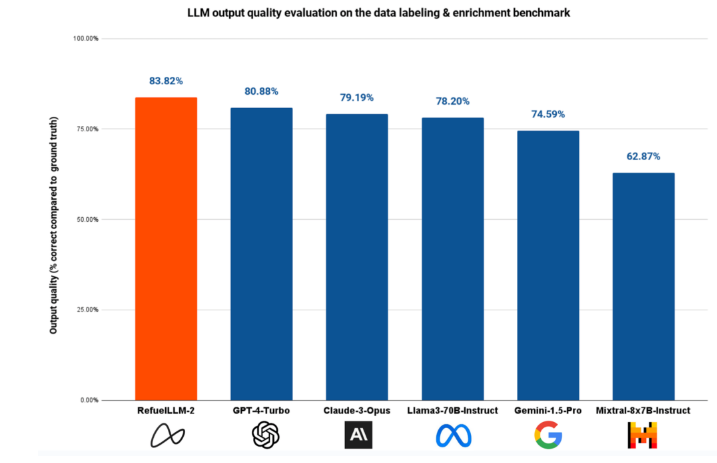
更为引人注目的是,RefuelLLM-2在数据丰富方面也有着出色的表现。它能够根据现有数据自动补充缺失信息或提供额外上下文,增加数据的价值和可用性。这一功能对于数据分析和挖掘具有重要意义,可以帮助企业更好地利用数据资源,发现潜在商机。
在性能方面,RefuelLLM-2同样表现出色。在约30项数据标注任务的基准测试中,RefuelLLM-2以83.82%的准确率优于所有其他最先进的大型语言模型,包括GPT-4-Turbo和Claude-3-Opus。这一成绩充分证明了RefuelLLM-2在数据标注和清洗领域的卓越性能。
为了满足不同用户的需求,Refuel AI还推出了RefuelLLM-2-small。该模型基于Llama3-8B模型,提供了一个成本更低、运行更快的选项,同时保持了高性能。它支持高达8K的输入上下文长度,适合处理中等规模的数据集。对于需要处理大量数据但预算有限的用户来说,RefuelLLM-2-small无疑是一个理想的选择。
在训练方面,RefuelLLM-2和RefuelLLM-2-small都经过了严格的训练和优化。两款模型都在超过2750个数据集上进行训练,涵盖了分类、阅读理解、结构化属性提取和实体解析等任务。通过两阶段的训练方法,包括指令调整训练和更长上下文的输入训练,RefuelLLM-2在基本数据处理任务中表现出色,并能有效处理长上下文输入。
AI旋风认为,Refuel AI的这一创新为数据标注和清洗领域带来了新的解决方案。通过先进的AI技术,RefuelLLM-2和RefuelLLM-2-small能够自动化和优化大规模数据处理流程,提高数据质量和处理效率。未来,随着人工智能技术的不断发展,我们有理由相信Refuel AI将继续引领数据标注和清洗领域的技术革新,为企业和用户提供更加智能、高效的数据处理方案。
 渝公网安备50019002504809号
渝公网安备50019002504809号